Automotive products: Market overview, data sources, and regional leaders
The automotive products market, spanning car and motorcycle parts, accessories, consumables, tools, and tires, is vast, resilient, and increasingly digital-first.
Publishers and book retailers alike depend on accurate data to guide decisions. With the right datasets, it’s possible to align with reader preferences, optimize pricing strategies, and ensure the right titles reach the right shelves at the right time.
Sourced from public platforms and enriched through ethical web scraping and advanced analytics, these datasets provide visibility into metadata, pricing, formats, reader sentiment, sales velocity, availability, and more.

Book datasets are comprehensive, structured collections of information related to published books. They may include:
Depending on your needs, these datasets can be used for cataloging, machine learning, market analytics, AI training, or content personalization.
Includes foundational details like title, author, publisher, ISBN, publication date, genre, language, and format.
Aggregated reader sentiment data for:
Sources: Goodreads, Amazon Reviews
Reflect a book’s performance via:
Book covers are essential for:
Especially valuable for scholarly publishers, including:
Sources: Semantic Scholar, OpenAlex
Track the rise and fall of genres, discover high-performing authors, and analyze format preferences across markets.
SSA Group aggregates this at scale—saving editorial teams weeks of manual research.
Compare pricing models, release windows, and bundling tactics used by competitors.
Automate competitor monitoring to refine your go-to-market approach.
Gauge reader appetite for new voices and themes by analyzing engagement, review volume, and sentiment.
SSA Group helps identify hidden demand and untapped subcategories.
Analyze reviews to pinpoint loved and disliked tropes, favored pacing or tone, and unmet expectations.
Our data equips marketers and editors to align product messaging with real audience needs.
Book retailers—both online and brick-and-mortar—can extract enormous value from book datasets to enhance customer experience, streamline logistics, and drive conversion.
At SSA Group, we specialize in delivering high-quality, customized books datasets and automated web scraping services for both publishing and retail sectors.
Using structured data extraction from publicly available platforms like Goodreads, Open Library, and others, we offer tailored datasets that include:
Explore our services: SSA Group – Datasets & Website Scraping Services
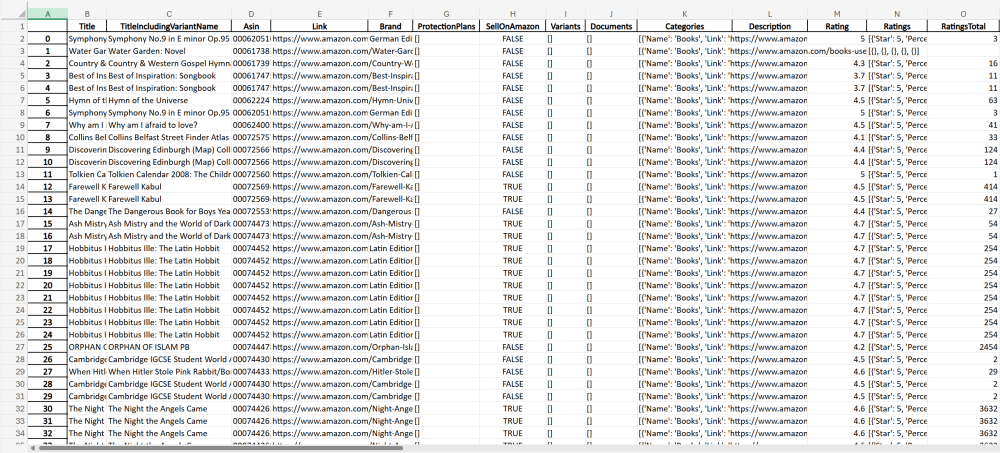
And for teams that prefer ready-to-use Amazon books dataset that can be integrated into AI and BI workflows immediately, Datasets.store is a practical option. It provides ecommerce datasets with flexible delivery formats and update frequency options, from one-time downloads to recurring updates.
In both publishing and retail, book datasets are a strategic multiplier—empowering data-driven decisions across acquisition, pricing, marketing, inventory, and content development.
At SSA Group, we provide fully customized datasets from any public source, built to fit your exact specifications. Whether you’re analyzing metadata, pricing trends, reviews, or stock levels across global markets, we can deliver the data infrastructure you need to grow.
Ready to turn book data into business intelligence?
Let’s explore how we can support your next chapter: Contact SSA Group

The automotive products market, spanning car and motorcycle parts, accessories, consumables, tools, and tires, is vast, resilient, and increasingly digital-first.

The Beauty & Personal Care market is rapidly evolving — fragmented across private-label drugstores, prestige specialists, and fast-scaling e-commerce platforms.
you're currently offline